
Why We Started Dogfooding Shipbook — and What We Found
There is an old principle in software: use what you build. The industry calls it dogfooding — short for "eating your own dog food," meaning if you build a product, you should use it yourself. The logic is simple: if it is not good enough for you, it is not good enough for your customers. If you are not experiencing your own product the way your users do, you are flying blind. You can read every support ticket, study every metric, and still miss what it actually feels like when something goes wrong.
For years, Shipbook was a logging platform built for mobile apps. Our SDKs covered iOS, Android, Flutter, and React Native. Our users were mobile developers — and so was I. Before Shipbook, I was VP R&D at a mobile app services company, which is where the idea for Shipbook was born. But time passes. As the product grew, I spent less time inside mobile apps and more time building the platform itself — the web console, the backend, the infrastructure. Even though Shipbook was born from the mobile world, our own day-to-day work had moved beyond it. Our stack — a web console, a Node.js backend — lived outside the reach of our own tools. We could see our users' logs, but we could not see our own.
That had to change.
Building the SDKs We Needed
We added a browser SDK and a Node.js SDK to our JavaScript SDK family. The main motivation was to close the gap between us and our users. We wanted to instrument our own web console and backend services with Shipbook, to see our own errors, our own warnings, our own performance issues flow through the same pipeline our customers rely on.
The moment we deployed them, something shifted. Issues that had previously been abstract — a user reporting a vague problem, a spike in an error metric — became concrete. When the console threw an error, we saw it in our own logs. When the backend hit an edge case, we felt it. There is a fundamental difference between reading a report about a problem and encountering it yourself while doing your own work.
The Difference Between Hearing and Feeling
When a user files a bug report, you investigate. You look at the evidence, reproduce the issue if you can, and fix it. It is a rational process. But when you yourself hit that same issue — when you are in the middle of debugging something else and the console behaves unexpectedly — you feel it differently. The urgency is not simulated. The frustration is not secondhand. You do not need a priority score to know this needs fixing.
This is the real argument for dogfooding. It is not just about finding bugs. It is about changing your entire relationship to your product. When you use it daily, you do not only discover what is broken — you discover what is missing. You feel the features that should exist but do not. You notice the workflows that are clunky, the information that is hard to find, the capabilities you keep wishing you had. No feature request from a user can replicate that intuition. Dogfooding drives not just quality, but product direction.
We started noticing things our users had probably noticed for months. Small annoyances, missing capabilities, rough edges that individually seemed minor but collectively degraded the experience. The kind of things that rarely make it into a support ticket because no single one is worth reporting — but that erode trust over time.
When Claude Met Our Logs
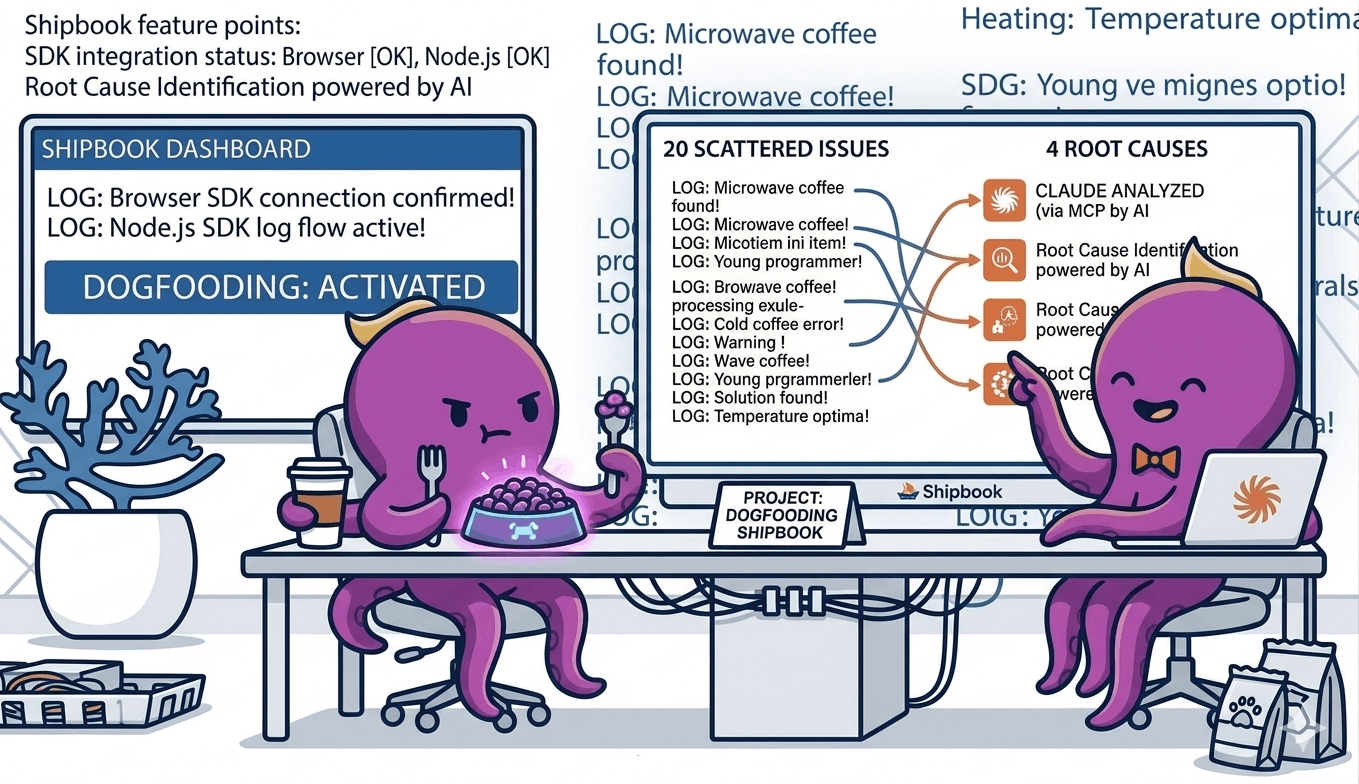
The most surprising chapter came when we connected Claude to our Shipbook data through an MCP server. We gave it access to our Loglytics — the aggregated error analytics that Shipbook computes across sessions — and asked it to analyze the issues.
Loglytics was already doing a good job — it had identified around twenty distinct error patterns, grouped and ranked by frequency and impact. That alone is valuable. But what happened next is where the real power showed up.
Claude processed the full Loglytics output and consolidated the twenty issues into four root causes. Not four categories — four actual underlying issues. And then it did not stop at the analysis. It went ahead and fixed them directly in the code.
This is where the combination of Shipbook Loglytics, MCP, and Claude Code becomes something greater than its parts. Loglytics surfaces the problems. MCP gives Claude access to that data. And Claude Code has the ability to reason about the issues and write the fixes. The entire loop — from detection to diagnosis to resolution — happened without manual triage, without prioritization meetings, without context-switching between tools.
Ground Truth Changes Everything
This experience crystallized something we had been thinking about for a while: AI is most powerful when it has ground truth to work with. Give a model a vague question and you get a vague answer. Give it structured, real-world data — actual logs, actual error patterns, actual stack traces — and it becomes remarkably precise.
Our logs were not just records of what happened. They were the ground truth that made Claude's analysis trustworthy. Every conclusion it drew was anchored in real data from real sessions. There was no hallucination risk because the model was not speculating — it was reasoning over facts.
This is where logging and AI intersect in a way that feels genuinely new. Logs have always been valuable for debugging. But when you feed them to a model that can reason about patterns at scale, they become something more: a foundation for proactive quality improvement.
Fixing Issues Before Users Complain
The most valuable outcome was not just finding the four root causes. It was fixing them before our users had to ask. We knew from the data that these issues were affecting real sessions. We could see the frequency and the impact. But no one had filed a ticket yet — or if they had, it was buried in vague descriptions that did not point to the root cause.
By dogfooding our own system and letting AI analyze the results, we moved from reactive support to proactive improvement. We did not wait for complaints. We saw the problems ourselves, understood them deeply, and resolved them.
This is the cycle we now believe every product team should aim for: use your own product, instrument it thoroughly, feed the data to AI, and fix what it finds — before your users have to tell you something is wrong. It is a higher standard of quality, and it is only possible when you are willing to be your own harshest critic.
The Lesson
Building a product you do not use yourself is like writing a book you never read. You might get the structure right. You might catch the obvious errors. But you will miss the experience — the pacing, the friction, the moments where things just do not feel right.
We should have dogfooded Shipbook sooner. Now that we have, we cannot imagine going back. Every issue we find in our own usage is an issue we fix for everyone. And with AI turning our logs into actionable insights, the gap between "something is wrong" and "here is exactly what to fix" has never been shorter.